unsloth
฿10.00
unsloth unsloth multi gpu You can now reproduce DeepSeek-R1's reasoning on your own local device! Experience the Aha moment with just 7GB VRAM Unsloth reduces GRPO training memory
pypi unsloth The Unsloth Prize For the best fine-tuned Gemma 3n model created using Unsloth, optimized for a specific, impactful task $10,000 The Google
unsloth In this tutorial, we will explore how to fine-tune an LLM using Unsloth and Hugging Face From installation to preparing your dataset and running inference on
unsloth pypi unsloth gpt-oss-20b-GGUF · xauraAffine-qnew32 xaura Affine-qnew32
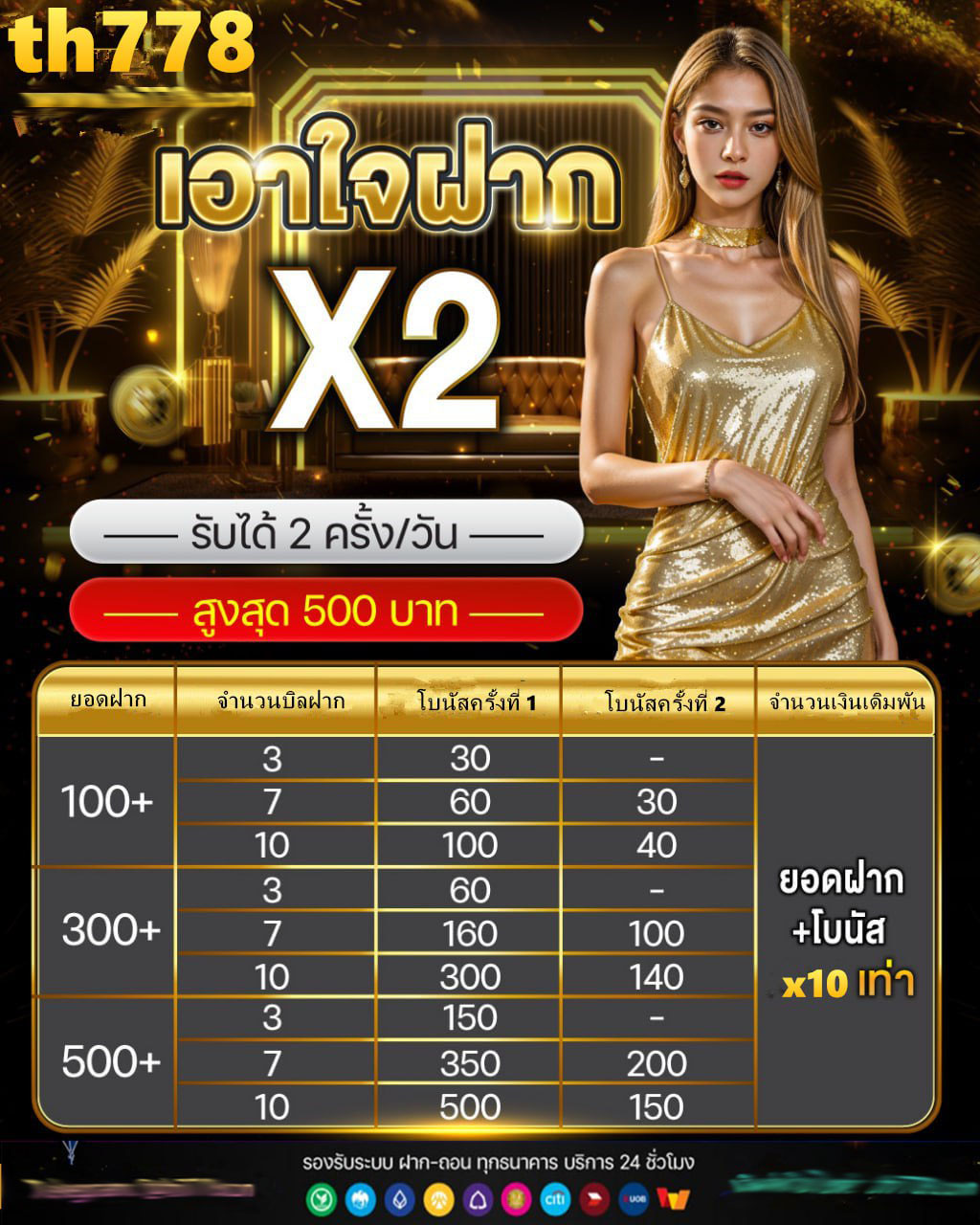
Add to wish listProduct description
unslothunsloth ✅ Unsloth AI: Open-source fine-tuning & reinforcement - unsloth,You can now reproduce DeepSeek-R1's reasoning on your own local device! Experience the Aha moment with just 7GB VRAM Unsloth reduces GRPO training memory&emspUnsloth AI is a boutique AI studio founded by brothers Daniel and Michael Han, dedicated to helping you train, fine-tune and deploy large